
或:如何搞懂 CLIP/SigLip 与图像向量编码
tl;dr: 我用 SigLip/CLIP 给图片做向量嵌入,顺手造了个 meme 搜索引擎。太好玩,也学到不少东西。
这几年我一直在折腾各种“实战 AI”小工具,其中最像魔术的一环就是向量嵌入。第一次见到 Word2Vec 之类的技术时,我整个人直接被震住,简直像变戏法。
前阵子在 Hacker News 刷到一个极简小项目,效果却惊艳到爆。作者爬了一堆 Tumblr 图片,用 SigLip 做嵌入,再搞了个“点图就看相似图”的网站,活像魔术。我完全不知道怎么实现,但感觉触手可及。
趁着这股冲劲,我决定搞清楚“这一切到底怎么运作”。
wut(啥?)
如果你从没接触过向量嵌入、CLIP/SigLip、向量数据库之类的概念——别慌,我之前也差不多。
在看到 HN 上那个 hack 之前,我对向量嵌入、多模态嵌入或向量数据库没怎么深究。以前随手用过 FAISS(Facebook 的向量库)和 Pinecone(付费,$$)做实验,但也只是“跑通→测试通过→结束”。
老实说,我现在还是几乎搞不懂向量到底是什么,LOL。没做这次实验前,我真想不到除了 RAG 或其他 LLM 流程还能怎么用它。
我是那种必须边做边学的人,最好结果还得足够酷炫——这次正合我胃口。
WTF 术语速查
发稿前让几个朋友先看,他们直接问“X 是啥?”下面这张小表方便新手预习:
- 向量嵌入(Vector Embeddings)——把文本或图像转换成数值向量,从而可高效进行相似性检索。
- 向量数据库(Vector Database)——专门存储并检索这些向量的数据库,帮你迅速找出相似项。
- Word2Vec——早期的“神技”,把词语转成向量,可做“找同义词”“探索词间关系”。
- CLIP——OpenAI 的模型,可把图像和文本同时编码成向量。
- OpenCLIP——CLIP 的开源实现,让任何人都能自由使用并继续开发,无需额外授权。
- FAISS——Facebook 推出的高效库,用来管理与检索大规模向量集合,让查找又快又省事。
- ChromaDB——一款向量数据库,用来高速存取图像/文本向量,并快速返回相似结果。
保持简单,Harper
这就是个非常直白的 hack。我就他妈瞎折腾,不指望它多可扩展,但想让你也能轻松跑起来。
目标之一:所有东西都在我笔记本本地跑。既然 Mac 的 GPU 这么豪华,就让它们好好烤一烤吧。
第一步是写爬虫(crawler),让它扫描一个图片目录。我用 Apple Photos,所以没有现成的“图片文件夹”。但我有一整桶保密级 meme(别告诉别人)。导出聊天记录,把图片挪到目录里,砰——测试集到手。
爬虫
我写了“史上最烂爬虫”。准确说,是让我和 Claude 合作写的。
大致流程:
- 获取目标目录下的文件列表,并存进 msgpack 文件
- 读取 msgpack,遍历每张图写进 SQLite,记录元数据:
- hash
- 文件大小
- 文件路径
- 拍摄/地理位置(location)
- 遍历 SQLite,用 CLIP 生成每张图的向量嵌入,并写回数据库
- 再遍历 SQLite,把向量和图片路径插入 Chroma 向量数据库
- 收工
这显然挺浪费:本来直接遍历→嵌入→塞进 Chroma 就行(选 Chroma 因为免费,无需运维)。
我之所以这么设计,是因为:
- meme 之后我又爬了 14 万张照片,希望程序崩了能续跑
- 即使断电也能快速恢复
- 我真的很爱写循环
虽然流程啰嗦,但它跑得稳如老狗。目前已处理超 20 万张图片。
嵌入系统
图像编码的过程也很有趣。
我先用 SigLip 写了个简单 Web 服务,上传图片即可拿到向量。跑在工作室的 GPU 机器上,速度算不上快,但仍旧比我在本地跑 OpenCLIP 快多了。
可我还是想本地跑。想到苹果的 ml-explore 里有示例,果然有个CLIP 实现,而且快得要命(fast af):用大模型也比 4090 还快,简直炸裂。
剩下的就是把它封装成脚本里可调用的模块。
MLX_CLIP
我和 Claude 拿苹果示例改成一个小 Python 类,本地跑毫无压力:模型不存在就下载、转换,然后直接用。
仓库在这儿:https://github.com/harperreed/mlx_clip
我对效果相当满意。我知道大多数人其实已经知道这点,但还是要再说一遍:Apple Silicon 真的快 af。
用法超简单:
import mlx_clip
# 初始化模型
clip = mlx_clip.mlx_clip("openai/clip-vit-base-patch32")
# 编码图片
image_embeddings = clip.image_encoder("assets/cat.jpeg")
print(image_embeddings)
# 编码文本
text_embeddings = clip.text_encoder("a photo of a cat")
print(text_embeddings)我个人更喜欢 SigLip,毕竟效果更好;但这只是一个 POC(Proof of Concept),我也不想长期维护。如果有人知道怎么把 SigLip 跑在 MLX 上——hmu。我也不想重写 OpenCLIP;理论上它在 Apple Silicon 上也能跑得不错。
接下来干嘛
既然向量都塞进向量数据库了,就该做界面。我直接用 ChromaDB 的 query 功能来找相似图。
拿一张图,取向量,丢给 Chroma。Chroma 会返回一个按相似度递减排序的图片 ID 列表。
我把所有东西封装成一个 Tailwind CSS + Flask 的小应用。效果真的不可思议。如果放在 2015 年,要花多少人力都难以想象;而我总共花了不到 10 小时,就轻松搞定。
meme 概念搜索
提醒一下,初始数据集是一万两千张 meme。
先看这一张:

编码→查询→得到这些:

再看一个:

结果:

点来点去根本停不下来。
Namespaces?
光是“点图找相似图”已经很酷,但还不足以让我大喊“卧槽”。
真正震撼的是:用同一个模型把文字也编码成向量,再去搜图。
这会让大脑直接短路:图搜图已经够酷,多模态搜索就更像魔术。
例如:
搜索 money,取文字向量查 Chroma,结果: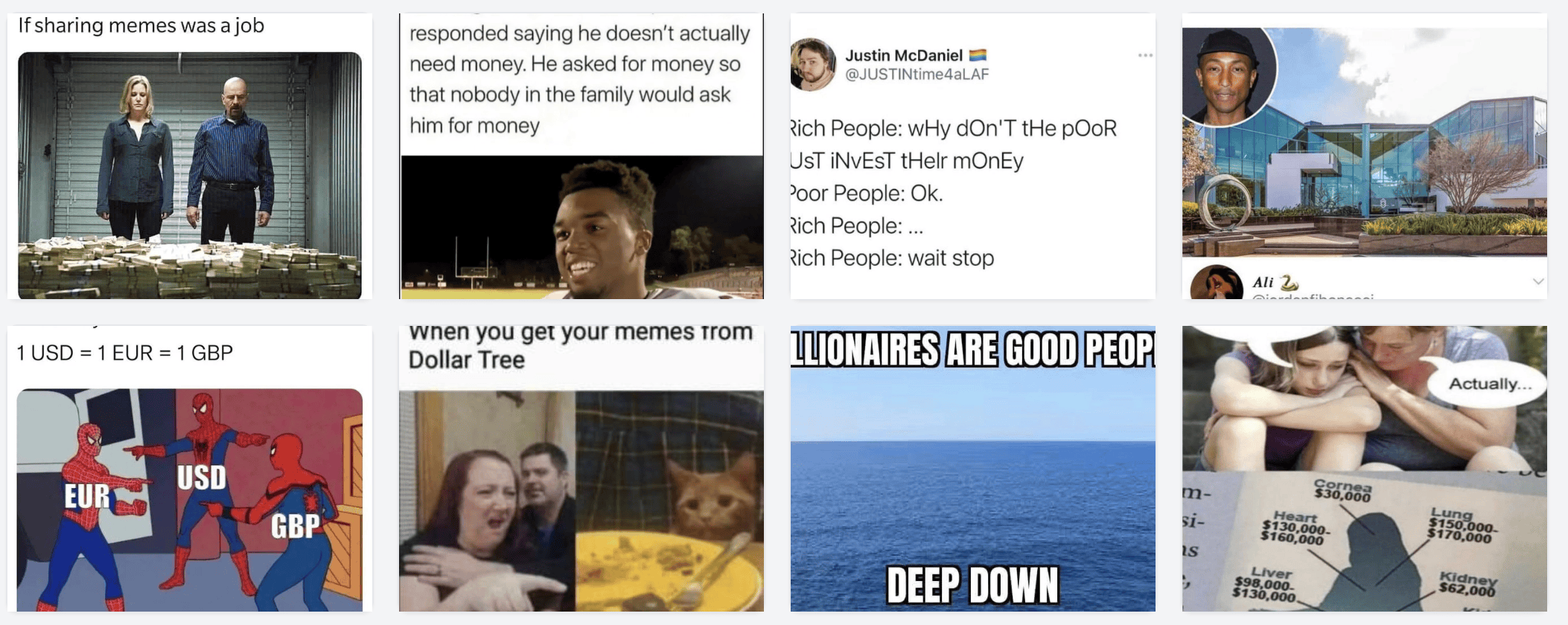
搜索 AI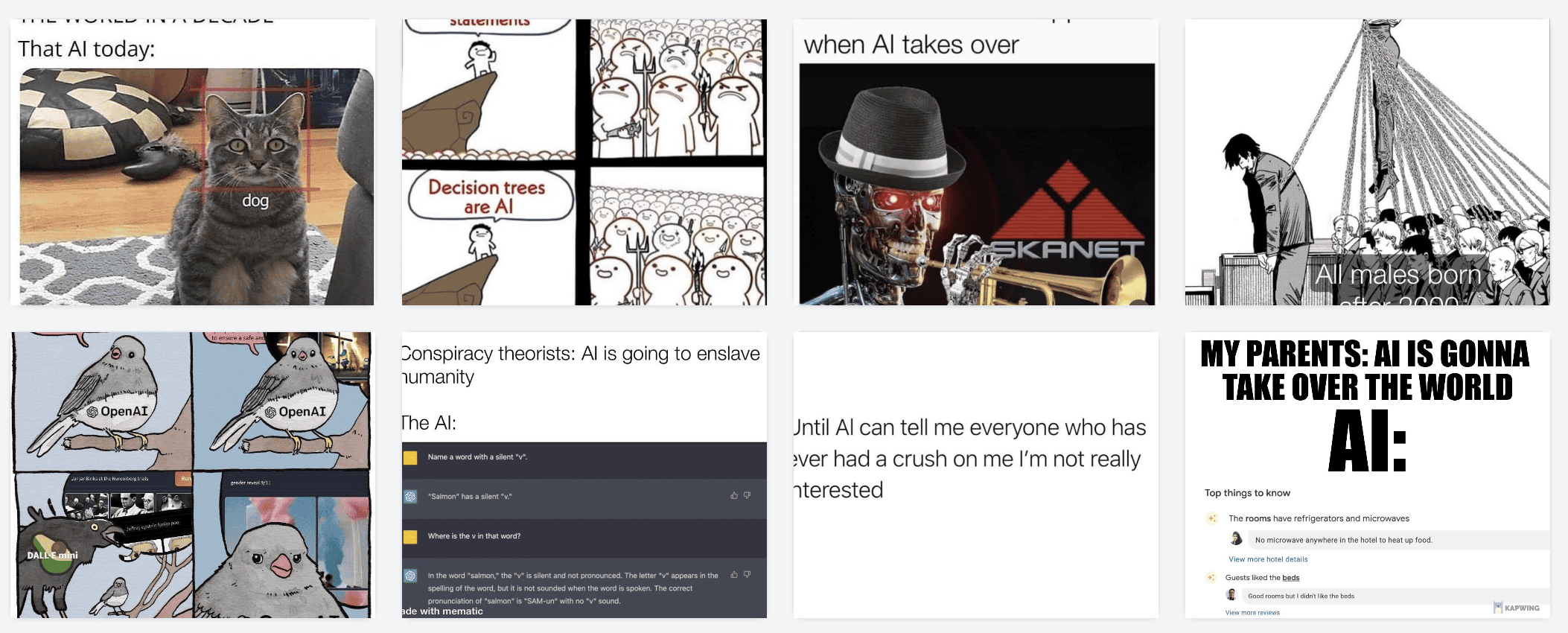
搜索 red(这是颜色?生活方式?还是俄罗斯?)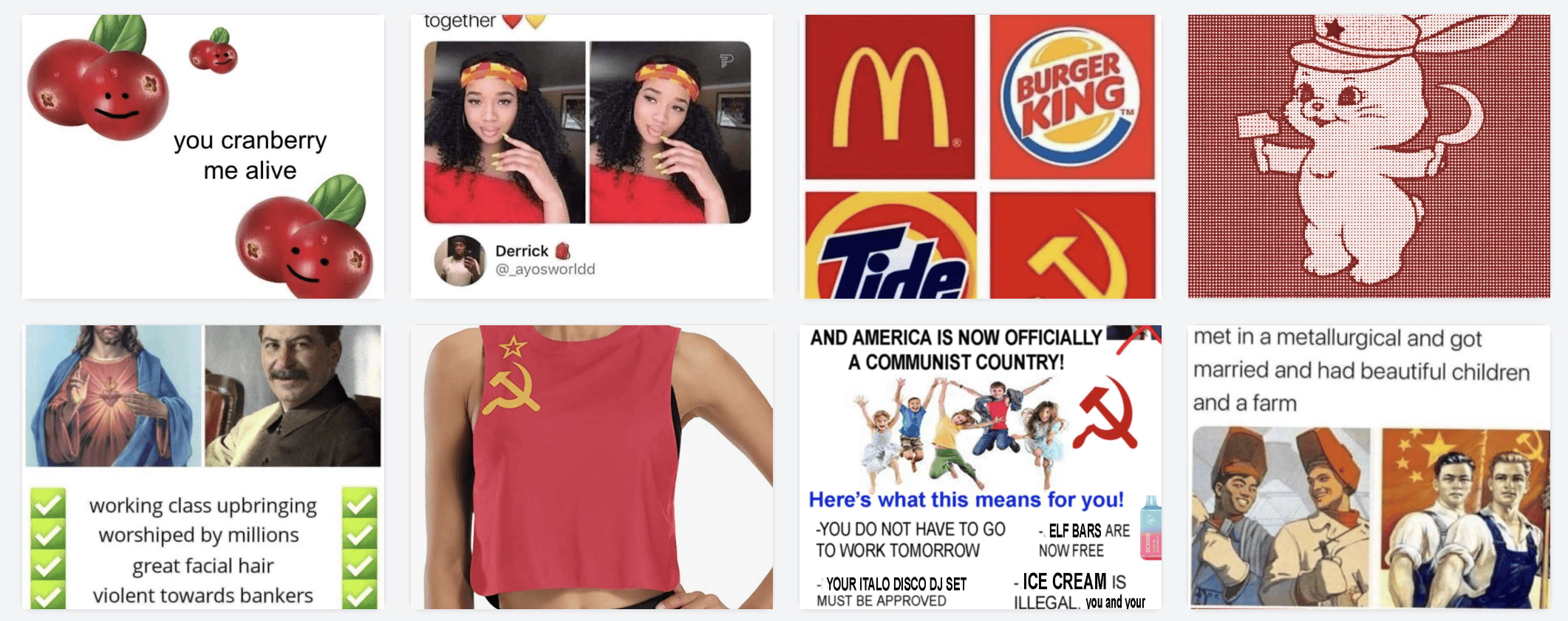
如此等等,永远玩不完。要找“写博客”相关的 meme?
(我很自知,但完全不在意,LOL)
用在照片库里咋样?
爽爆了。
强烈建议拿你的照片库跑一遍。我把 Google Photos Takeout 全下回来,解压到外置盘。Takeout 里重复文件巨多,只好写脚本清理。然后把脚本目标目录换成照片目录,让它跑就行。
我有约 14 万张照片,大概 6 小时跑完。效果惊人。
随便举几个例子
显而易见,相似度很高(我也有重复问题)
家里养过很多贵宾犬
还能搜地标。我完全不知道自己在飞机上拍到过富士山!
接着找相似的富士山
搜城市
搜情绪。我显然很爱做出惊讶表情,所以有一堆惊讶照
搜小众题材,比如 low rider(这些在涩谷拍的)
或者搜难描述的效果,比如 bokeh
翻着翻着还能发现被遗忘的好片,比如我 2017 年拍的 Baratunde:

这东西马上到处都是
我敢说各大照片 App 很快都会集成这个。Google Photos 可能早就做了,只是被他们搞得太“Google 味儿”,以至于没人察觉。
要是我在做任何跟图片相关的大型产品,会立刻上线这条流水线,看看能解锁什么新花样。
你也能免费用
源码在这:harperreed/photo-similarity-search。
随便玩,略微 hacky。
最好用 conda 之类建虚拟环境。前端 Tailwind CSS,后端 Flask,代码 Python。我是作者 Harper Reed。
给你的挑战!
谁来做个 Mac 原生小应用帮我整理照片?无需上传云端,本地跑就行:指向图库,点一下“爬取”。
可以加一些花活:
- Llava/Moondream 自动生成描述
- 关键词/标签
- 向量相似度
- …等等
必须本地、原生、简单、高效。最好还能接 Lightroom、Capture One 或 Apple Photos。
我真的需要它。快做吧,让 AI 魔法帮我们重温那些被遗忘的好照片。
进阶题:Lightroom 预览 JPEG 恢复
我的黑客朋友 Ivan 在旁边看我折腾,也立刻感受到了魔力。他的照片都在外置硬盘,但本地有 Lightroom 预览文件。他写了个脚本把预览里的缩略图和元数据提取出来,保存到外置盘。
然后我们跑向量爬虫——砰——就搞定,也能做相似搜索,完美。
恢复 Lightroom 照片(至少缩略图)
Ivan 的脚本非常赞。如果你硬盘炸了,只剩 lrpreview 文件,这脚本至少能救回低分辨率图。
脚本在此:LR Preview JPEG Extractor
谢谢阅读
一如既往,hmu,一起聊 AI、电商、照片、hifi、hacking 等等。
如果你在芝加哥,来玩!